20.3. Les goulots d'étranglement d'accès aux données
Les systèmes modernes ont fréquemment besoin d'accéder aux données d'une manière hautement concourante. Par exemple, d'importants serveurs FTP ou HTTP peuvent supporter des milliers de sessions concourantes et avoir de multiple connexions à 100 Mbit/s vers le monde extérieur, et cela bien au-delà du taux de transfert soutenu de la plupart des disques.
Les disques actuels peuvent effectuer des transfert séquentiels de données jusqu'à une vitesse de 70 MO/s, mais ce chiffre a peu d'importance dans un environnement où plusieurs processus indépendants accèdent à un disque, où l'on pourra n'atteindre qu'une fraction de cette valeur. Dans de tels cas il est plus intéressant de voir le problème du point de vue du sous-système des disques: le paramètre important est la charge que provoque un transfert sur le sous-système, en d'autres termes le temps d'occupation du disque impliqué dans le transfert.
Dans n'importe quel transfert, le disque doit tout d'abord positionner les têtes de lecture, attendre le passage du premier secteur sous la tête de lecture, puis effectuer le transfert. Ces actions peuvent être considérées comme étant atomiques: cela n'a aucun sens de les interrompre.
Considérons un transfert typique d'environ 10 KO: la génération actuelle de disques hautes performances peuvent positionner leurs têtes en environ 3.5 ms. Les disques les plus véloces tournent à 15000 tr/minute, donc le temps de latence moyen de rotation (un demi-tour) est de 2 ms. A 70 MO/s, le transfert en lui-même prend environ 150 μs, presque rien comparé au temps de positionnement. Dans un tel cas, le taux de transfert effectif tombe à un peu plus de 1 MO/s et est clairement hautement dépendant de la taille du transfert.
La solution classique et évidente à ce goulot d'étranglement est “plus de cylindres”: plutôt que d'utiliser un gros disque, on utilise plusieurs disques plus petits avec le même espace de stockage. Chaque disque est en mesure d'effectuer un transfert indépendamment des autres, aussi le taux de sortie augmente d'un facteur proche du nombre de disques utilisés.
L'amélioration du taux réel de sortie est, naturellement, inférieure au nombre de disques impliqués: bien que chaque disque soit capable de transférer en parallèle, il n'y a aucun moyen de s'assurer que les requêtes sont distribuées équitablement entre les disques. Inévitablement la charge d'un disque sera plus importante que celle d'un autre.
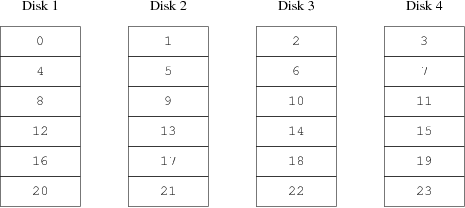
La répartition de la charge sur les disques dépend fortement de la manière dont les données sont partagées entre les disques. Dans la discussion suivant, il sera pratique de penser au stockage disque en tant qu'un grand nombre de secteurs qui sont adressables par l'intermédiaire d'un nombre, plutôt que comme les pages d'un livre. La méthode la plus évidente est de diviser le disque virtuel en groupes de secteurs consécutifs de taille égale aux disques physiques individuels et de les stocker de cette manière, plutôt que de les prendre comme un gros livre et de le déchirer en petites sections. Cette méthode est appelée concaténation et a pour avantage que les disques n'ont pas besoin d'avoir de rapport spécifique au niveau de leur taille respective. Cela fonctionne bien quand l'accès au disque virtuel est réparti de façon identique sur son espace d'adressage. Quand l'accès est limité à une petite zone, l'amélioration est moins marquée. Figure 20-1 décrit la séquence dans laquelle les unités sont assignées dans une organisation par concaténation.
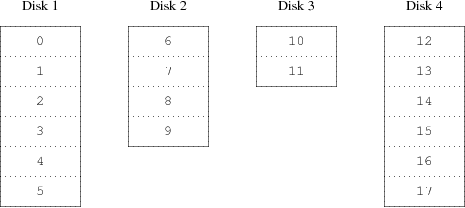
Une organisation alternative est de diviser l'espace adressable en composants plus petits, de même taille et de les stocker séquentiellement sur différents périphériques. Par exemple, les 256 premiers secteurs peuvent être stockés sur le premier disque, les 256 secteurs suivants sur le disque suivant et ainsi de suite. Après avoir atteint le dernier disque, le processus se répète jusqu'à ce que les disques soient pleins. Cette organisation est appelée striping (découpage en bande ou segmentation) ou RAID-0 [1].
La segmentation exige légèrement plus d'effort pour localiser les données, et peut causer une charge additionnelle d'E/S quand un transfert est réparti sur de multiples disques, mais il peut également fournir une charge plus constante sur les disques. Figure 20-2 illustre l'ordre dans lequel les unités de stockage sont assignées dans une organisation segmentée.